
In our previous blog entries, we discussed translation hurdles (blog) and how parallel word databases can be helpful (blog). We now introduce what resources in lexical databases may be available.
Chilin now provides English-Chinese parallel sentences on the TAUS Data Marketplace. Two large datasets related to Pharmaceuticals and Biotechnology are now available. Chilin’s parallel sentence data is provided in TMX format and can easily be processed by machine learning systems specifically for custom neural machine translation.
Amsterdam based TAUS launched the TAUS Data Marketplace on November 12, 2020. It is a platform where data sellers can offer language data and where data buyers can browse and license data.
You can easily and anonymously see samples of Chilin’s data on the Data Marketplace. Instructions are described at the end of this blog. The samples screen is shown below.
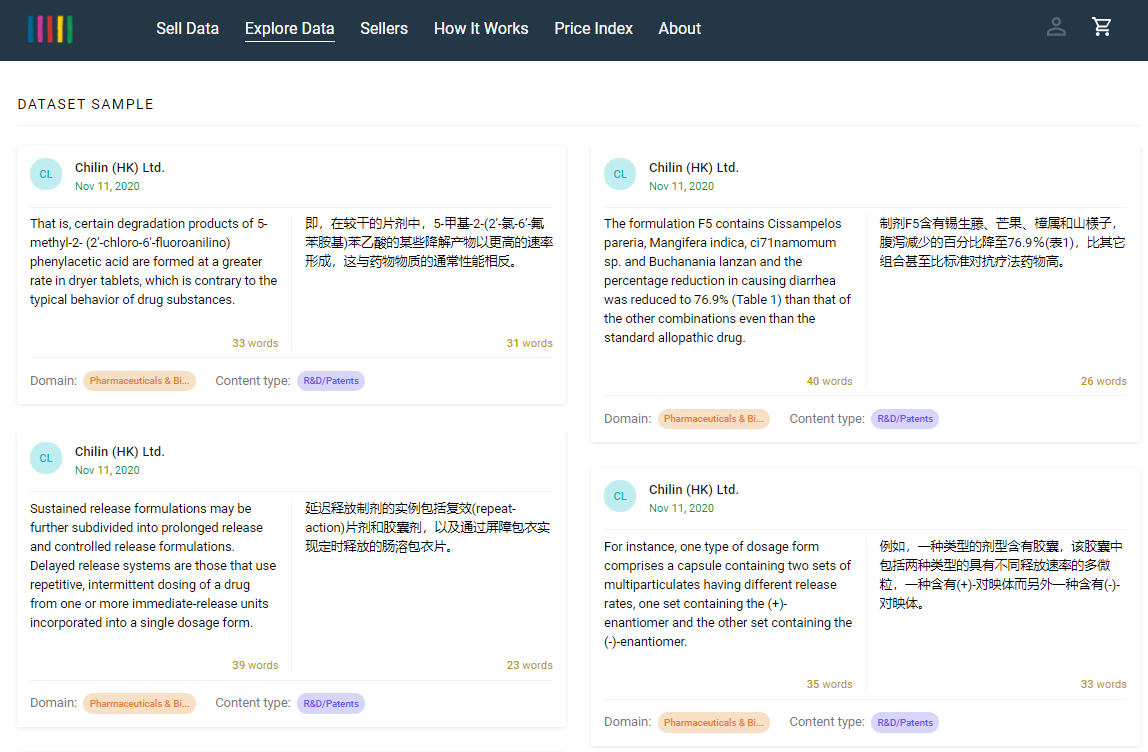
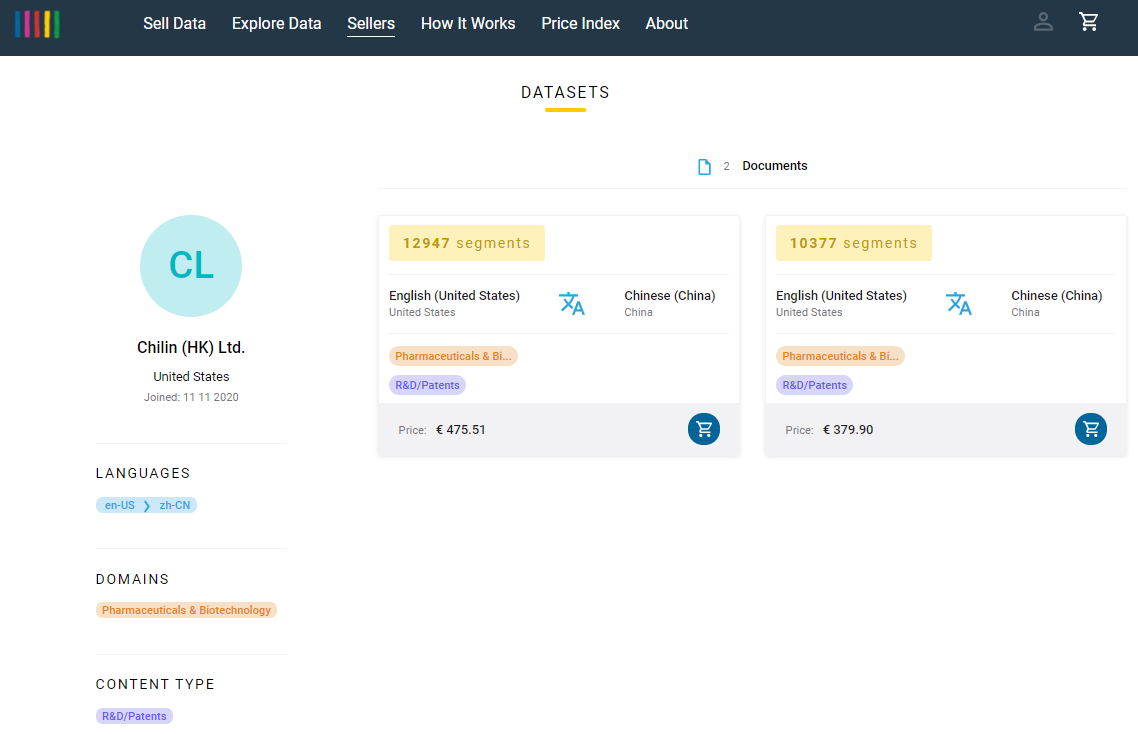
Chilin has many specialist databases in store. Two of them are recently launched on TAUS.
One dataset of contains 12,947 segments; 475,509 en-US words; and 401,629 zh-CN characters. It is based on the CPC Patent Classification category A61K which covers pharmaceuticals.
The second dataset contains 10,377 segments; 379,898 en-US words; and 327,637 zh-CN words. It is based on the CPC Patent Classification C12N which contains many biotechnology filings.
For information on sample data, availability and cost, please refer to this page.
How the Data is produced?
Chilin English-Chinese sentence pairs are derived from global patent data. Our database contains over 30 million sentence pairs. Domain specific datasets can be extracted based on patent classification. The most frequently occurring classifications (based on 2019 USPTO patent grants) can be found at 2019 Trends and Insights | IFI CLAIMS. A61K and C12N classifications are very popular, but trail behind the computer and telecommunications codes such as G06F (electrical digital data processing) and H04L (transmission of digital information).
If you are interested in larger datasets, or datasets in domains other than pharmaceuticals and biotechnology, please contact Chilin at here.
What can you do with this data? We will be offering one suggestion in our next blog post.